26 mars 2026
Site Reliability Engineering (SRE) : garantir la fiabilité et la performance des plateformes numériques
La fiabilité des plateformes numériques est aujourd’hui un enjeu central pour les entreprises, car leur disponibilité et leur performance sont des conditions essentielles pour garantir une expérience utilisateur de qualité. Pour répondre à ces exigences, de nombreuses organisations s’appuient sur le Site Reliability Engineering (SRE), afin de mettre en place un cadre concret pour piloter la fiabilité des plateformes dans la durée.
Introduction
Chez Datanumia, cette démarche contribue à renforcer la robustesse de nos plateformes à destination des entreprises et des collectivités : l’iBoard, notre plateforme de management énergétique, et le Building Management System (BMS), notre plateforme de pilotage. Elle se traduit notamment par l’évolution de nos pratiques de gestion du run, la mise en place d’un monitoring dédié et un suivi plus fin de la performance de nos services.
Cet article revient sur les fondamentaux du SRE et sur la manière dont cette approche permet de garantir la fiabilité et la performance de nos plateformes.
Qu’est-ce que le Site Reliability Engineering (SRE) ?
Le Site Reliability Engineering est une approche qui consiste à appliquer les principes de l’ingénierie logicielle à l’exploitation des systèmes en production. L’objectif est d’améliorer la fiabilité, la disponibilité et la performance des services numériques de manière mesurable et continue.
Plutôt que de considérer l’exploitation comme une activité distincte du développement, le SRE cherche à rapprocher ces deux mondes. Les équipes s’appuient sur des outils d’automatisation, des indicateurs de performance et des pratiques d’amélioration continue pour concevoir des systèmes capables de fonctionner de manière stable à grande échelle.
Ainsi, le Site Reliability Engineering transforme la gestion opérationnelle des plateformes : l’exploitation n’est plus seulement une réaction aux incidents, mais un levier d’amélioration continue de la qualité de service.
Pourquoi le SRE est devenu essentiel pour les plateformes numériques ?
Les plateformes numériques reposent aujourd’hui sur des architectures de plus en plus modulaires. Comme évoqué dans nos précédents articles sur l’architecture micro-frontend et la démarche API-First, les applications sont désormais composées de multiples briques autonomes, reliées entre elles par des interfaces et des services qui doivent communiquer de manière fiable.
Cette modularité et cette interopérabilité apportent davantage d’agilité et de capacité d’évolution aux produits digitaux. En contrepartie, elles introduisent aussi une complexité technique plus importante. Sans approche structurée, les équipes se retrouvent souvent dans une logique réactive, où les incidents sont traités au fur et à mesure qu’ils apparaissent. Il devient alors difficile d’identifier les causes des dysfonctionnements ou de mesurer réellement la qualité de service fournie aux utilisateurs.
Le Site Reliability Engineering apporte une réponse à ces défis en mettant en place un cadre pour observer les systèmes, mesurer leur fiabilité et améliorer durablement leur fonctionnement.
Structurer et piloter la fiabilité des plateformes grâce à la démarche SRE
L’approche Site Reliability Engineering conduit à faire évoluer la manière dont les plateformes sont exploitées au quotidien. L’objectif est de structurer et professionnaliser la gestion du run, afin d’améliorer durablement la fiabilité des services.
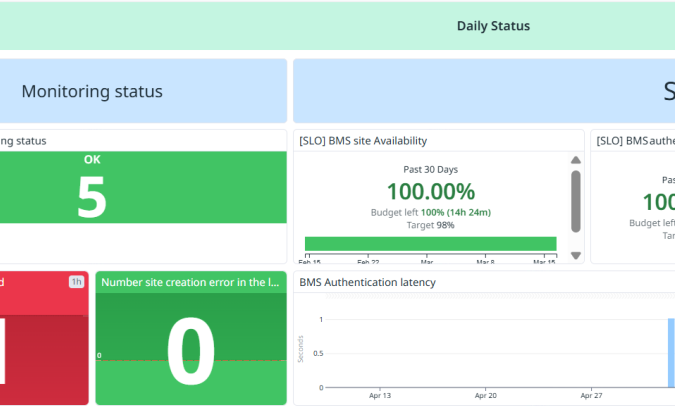
Pour y parvenir, la première étape consiste à se doter d’un monitoring dédié. En suivant en continu l’état des plateformes, il devient possible de détecter plus rapidement les anomalies et de comprendre ce qui dégrade réellement l’expérience, comme une hausse de la latence ou des données transmises en retard. Cette visibilité permet ensuite de transformer les constats opérationnels en actions d’amélioration intégrées aux roadmaps produit, afin d’en renforcer progressivement la fiabilité.
Le Site Reliability Engineering introduit également la notion d’error budget, qui représente la marge d’erreur acceptable au regard des objectifs de fiabilité. Cet outil sert de repère commun pour arbitrer entre la robustesse du service et la capacité à continuer à faire évoluer les plateformes.
Enfin, la démarche SRE s’attache à repérer les tâches opérationnelles répétitives, appelées toil. Il peut s’agir, par exemple, de relances manuelles répétées ou du traitement quotidien d’alertes récurrentes. L’enjeu est de décider, au cas par cas, si ces tâches doivent être automatisées, documentées ou intégrées directement au produit pour réduire la charge manuelle et sécuriser l’exploitation.
Les principes du SRE appliqués aux plateformes EMS et BMS de Datanumia
Sur les plateformes iBoard et BMS de Datanumia, l’approche Site Reliability Engineering commence par une définition claire de ce qu’est un service fiable. Nos équipes Produit, Sales et DSI travaillent ensemble pour préciser la valeur du service, les attentes en matière de disponibilité et les niveaux de performance attendus.
À partir de ces éléments, des indicateurs de fiabilité sont définis, notamment :
- les SLI (Service Level Indicators), qui mesurent l’état réel du service comme la disponibilité, la latence, ou le taux d’erreur,
- les SLO (Service Level Objectives), qui fixent des objectifs cibles sur ces indicateurs,
- les SLA (Service Level Agreements), qui formalisent les engagements de niveau de service vis-à-vis des clients.
Ces métriques permettent de suivre la santé des services, de mesurer la qualité réelle de la plateforme et d’aligner les engagements pris envers les utilisateurs.
Pour rendre ces objectifs actionnables, nous mettons en place un cadre de déploiement concret :
- Des ateliers de cadrage pour définir l’error budget et identifier les toil,
- Une documentation centralisée dans Confluence,
- Une traduction des décisions en backlog SRE priorisé sous forme de tickets, suivi via des points réguliers.
Côté opérations, l’approche se matérialise par un renforcement de l’observabilité des métriques et par une gestion plus structurée des incidents afin de mieux les détecter, les qualifier et les prioriser.
Conclusion : le Site Reliability Engineering, un levier durable de fiabilité
Le SRE apporte une approche structurée pour garantir la fiabilité et la performance des plateformes digitales. En définissant des objectifs précis, en mesurant la qualité de service et en faisant évoluer les pratiques de gestion du run, cette méthodologie permet d’améliorer progressivement la robustesse des systèmes.
Appliqué aux plateformes de Datanumia, le Site Reliability Engineering contribue à assurer une exploitation plus robuste des services et à renforcer la qualité des données et des fonctionnalités mises à disposition des utilisateurs. Il devient ainsi un levier pour garantir le haut niveau de fiabilité de nos plateformes.
À découvrir également

De l’écoute terrain à l’action : l’approche Customer Centric de Datanumia pour aligner produits et usages

Replatforming et stratégie de plateforme : construire, faire évoluer et itérer
