06 mai 2026
Replatforming et stratégie de plateforme : construire, faire évoluer et itérer
Une plateforme ne devient pas un frein du jour au lendemain. Les dérives s’installent progressivement : des déploiements plus longs, des services dupliqués, des coûts cloud qui augmentent sans gains mesurables. Dans ce contexte, le replatforming s’impose souvent. Mais migrer une application vers un nouvel environnement ne règle pas le fond du problème. Sans cadre structuré, la complexité revient.
Introduction
Le sujet concerne d’abord la manière de construire la plateforme : organisation des platform teams, structuration des services, choix d’architecture et mise en place d’une démarche de platform engineering. Le replatforming intervient ensuite, lorsque le socle existant ne permet plus de soutenir les usages. Puis vient une troisième étape, souvent sous-estimée : faire évoluer la plateforme dans le temps, au plus près des besoins.
Cette logique n’est pas théorique.
Chez Datanumia, elle s’est traduite par un programme de transformation de 18 mois, avec plusieurs centaines de services migrés vers une nouvelle plateforme cloud.
Ce retour d’expérience permet d’illustrer concrètement les enjeux et les arbitrages liés au replatforming.
Stratégie plateforme : structurer un socle utile aux équipes
Ce qu’une stratégie plateforme change concrètement
Une stratégie plateforme ne consiste pas à accumuler des outils cloud ou à moderniser une infrastructure existante.
Elle structure le platform engineering et clarifie le rôle de la plateforme dans la durée. Elle répond à un problème opérationnel précis : le temps perdu par les équipes à gérer des sujets techniques déjà traités ailleurs.
Dans une organisation sans cadre structuré, chaque équipe configure ses pipelines CI/CD, gère son infrastructure, arbitre ses choix de sécurité et met en place ses propres outils d’observabilité. Ces pipelines, souvent hétérogènes, complexifient la maintenance et ralentissent les cycles de déploiement.
Une plateforme bien conçue apporte une réponse directe. Elle fournit un socle commun, composé de services réutilisables, qui encadrent les pratiques sans les rigidifier. Les standards ne sont plus documentés, ils sont intégrés dans les outils et dans l’architecture, notamment en matière de sécurité, de conformité et de gestion des accès.
Ce changement produit des effets visibles :
- réduction du temps de mise en production
- meilleure maîtrise des coûts d’infrastructure
- amélioration de la fiabilité des environnements
Ce socle ne se limite pas au déploiement. Il intègre aussi des pratiques de Site Reliability Engineering pour garantir la stabilité du system, limiter les incidents et améliorer la performance globale.
Pourquoi une platform team devient indispensable
Une platform team ne fonctionne pas de manière isolée : elle nécessite une organisation dédiée et clairement structurée pour produire de la valeur.
Dans ce cadre, la platform team conçoit, maintient et fait évoluer les services internes utilisés par les équipes produit. Elle agit comme une équipe produit interne, avec des utilisateurs clairement identifiés. Dans cette organisation, elle devient le moteur opérationnel du platform engineering, en traduisant des besoins récurrents en services fiables, réutilisables et simples à activer.
Son rôle consiste à transformer des besoins récurrents en services standardisés. Elle réduit la complexité technique, améliore la cohérence des pratiques et permet aux équipes de se concentrer sur la valeur métier.
Sans cette structuration, la plateforme dérive rapidement. Les standards ne sont plus appliqués, les équipes recréent leurs propres solutions, et la dette technique réapparaît.
À l’inverse, une platform team bien positionnée réduit la charge cognitive des développeurs et améliore la capacité à délivrer rapidement des applications fiables.
La plateforme comme produit interne
Une plateforme doit être pensée comme un produit interne.
Cela implique un changement de posture. Les équipes de plateforme ne livrent pas seulement de l’infrastructure. Elles conçoivent une offre de services utilisée par d’autres équipes, avec des attentes comparables à celles d’un produit classique.
Concrètement, cela signifie :
- Une attention portée à l’expérience développeur (developer experience)
- Une documentation exploitable et à jour
- Des parcours simples pour accéder aux services
- Une logique de feedback continu
L’objectif est de réduire la complexité perçue par les équipes. Une plateforme efficace diminue la charge cognitive liée aux choix techniques, en proposant des standards directement intégrés dans les outils.
Elle permet ainsi aux équipes produit d’avancer plus vite, en limitant les frictions et les arbitrages techniques au quotidien.
Structurer un catalogue de services réellement utilisé
La stratégie plateforme ne repose pas uniquement sur des règles, mais sur un catalogue de services activables.
Ce catalogue constitue le socle opérationnel de la plateforme et doit répondre à des besoins concrets :
- Déployer une application
- Gérer une base de données
- Exposer une API
- Configurer l’observabilité
Dans cette logique, une démarche API-First facilite l’intégration entre applications et améliore la cohérence globale de l’architecture.
Chez Datanumia, la plateforme a été pensée comme un socle permettant aux équipes de déployer leurs services de manière autonome, tout en respectant des standards communs en matière de sécurité, de data et d’infrastructure.
Un tel catalogue de services ne se limite pas à une liste de briques techniques. Il doit proposer des parcours cohérents et adaptés aux besoins des équipes.
Dans les organisations les plus matures, ces services sont conçus comme des « golden paths ». Ils définissent des chemins standards pour répondre aux cas d’usage les plus fréquents, tout en garantissant un niveau de qualité homogène.
Une telle approche permet de concilier deux objectifs souvent opposés : standardiser les pratiques tout en laissant de la flexibilité sur les usages.
Une fois la plateforme structurée, la question n’est plus de construire, mais de savoir quand et comment la faire évoluer.
Replatforming : reconstruire les fondations quand la plateforme atteint ses limites
Reconnaître les signaux d’obsolescence
Une plateforme devient obsolète lorsqu’elle ne permet plus de répondre aux besoins des équipes et du business.
Les signaux sont opérationnels :
- Allongement des cycles de déploiement
- Dépendance accrue à l’infrastructure
- Difficulté à intégrer de nouveaux services
- Augmentation des coûts cloud sans gain de performance
Dans ce contexte, le replatforming s’impose comme une réponse logique. Il permet de faire évoluer un legacy system sans engager immédiatement une refonte complète.
Replatforming, rehosting, refactoring : comprendre les différences
Toutes les stratégies de migration ne répondent pas aux mêmes enjeux.
Le replatforming s’inscrit généralement dans une cloud migration strategy plus large. Il intervient lorsque les gains attendus d’une migration simple ne suffisent plus, mais que la refonte complète reste trop risquée ou trop coûteuse.
Cette approche permet de moderniser progressivement les applications, en intégrant certaines fonctionnalités cloud natives, tout en conservant une base existante. Elle offre un équilibre entre rapidité d’exécution, maîtrise des coûts et amélioration de la performance.

Le cas Datanumia : un programme de transformation sur 18 mois
Chez Datanumia, le replatforming s’inscrit dans un programme structuré sur un an et demi.
Le projet a débuté par une phase de cadrage co-construite avec les équipes, dans une logique proche de la Méthodologie Blueprint. Concrètement, ce travail a permis d’aligner les besoins métier, les contraintes techniques et la trajectoire de migration.
La migration s’est ensuite déroulée progressivement, avec plusieurs centaines de services B2B et B2C basculés vers une nouvelle plateforme cloud.
Ce programme a aussi permis de faire évoluer les pratiques de platform engineering, avec un socle plus standardisé, des parcours de déploiement plus lisibles et une meilleure autonomie des équipes.
Standardiser les pratiques et moderniser l’infrastructure
Le programme a permis d’harmoniser les environnements, du développement à la production, et de standardiser les composants techniques.
L’adoption du GitOps a structuré la gestion de l’infrastructure. Chaque modification passe par le code, ce qui garantit traçabilité et reproductibilité.
Le choix de services managés AWS a permis de réduire la charge opérationnelle, tout en intégrant des arbitrages FinOps pour maîtriser les coûts.
Sécuriser la migration dans le temps
Le projet s’est appuyé sur une organisation rigoureuse, avec un rétro-planning détaillé couvrant l’ensemble des environnements. Les étapes de validation ont été formalisées et les responsabilités clairement définies.
Les mises en production ont été encadrées par des jalons Go/NoGo, des procédures de déploiement et des scénarios de rollback. Une grande partie des opérations critiques a été anticipée avant les bascules, ce qui a permis de limiter les risques.
Un impact direct sur les équipes
Les équipes déploient plus rapidement, accèdent plus facilement à l’infrastructure et s’appuient sur des services standardisés. La plateforme devient un levier d’autonomie et non une contrainte.
À ce stade, la question change. Une fois le replatforming réalisé, la plateforme doit continuer à évoluer pour rester alignée avec les besoins.
Après le replatforming : faire vivre la plateforme dans la durée
Passer de la migration à l’itération
Le replatforming ne constitue pas une finalité. Il s’inscrit dans une cloud migration strategy plus large, qui vise à faire évoluer la plateforme dans le temps.
Une fois la migration terminée, un nouveau cycle commence. Les usages évoluent, de nouvelles applications apparaissent, et les contraintes techniques changent. Sans une dynamique d’évolution continue, les mêmes problèmes finissent par réapparaître : complexité croissante, dette technique, perte d’efficacité.
La plateforme ne peut donc plus être pensée comme un projet ponctuel. Elle devient un produit interne, piloté dans la durée par une platform team, avec des itérations régulières.
Se rapprocher des utilisateurs de la plateforme
La valeur d’une plateforme dépend directement de son adoption. Ses utilisateurs sont connus : équipes de développement, data et exploitation.
Après un replatforming, un décalage peut apparaître entre ce qui a été conçu et ce qui est réellement utilisé. Certains services restent peu exploités, ou d’autres sont contournés pour répondre à des besoins spécifiques.
Réduire cet écart suppose un travail continu. Il s’agit d’observer les usages, d’identifier les points de friction et d’adapter les services en conséquence.
Améliorer la gestion des données
Le passage à un cloud environment met souvent en évidence des limites dans la gestion des data.
Au-delà de l’infrastructure, la plateforme doit permettre de structurer les flux de données, de garantir leur qualité et de répondre aux exigences de sécurité et de compliance. Elle devient un élément central dans la capacité à exploiter la donnée à l’échelle.
Chez Datanumia, cet enjeu est structurant. La plateforme supporte des cas d’usage liés à la performance énergétique, ce qui implique une gestion rigoureuse des données et de leurs dépendances entre systèmes.
Développer la plateforme dans le temps : roadmap et gouvernance
La plateforme doit évoluer en continu, mais cette évolution doit être pilotée.
Une roadmap permet de structurer les priorités et d’aligner les évolutions avec les besoins métier. En parallèle, une gouvernance claire encadre les choix techniques et garantit la cohérence du system dans le temps.
La platform team joue ici un rôle central. Elle arbitre entre standardisation et besoins spécifiques, en tenant compte des contraintes des équipes et des objectifs globaux.
Dans la pratique, cet équilibre est délicat. Une plateforme trop rigide pousse les équipes à contourner les standards. À l’inverse, une plateforme trop flexible recrée de la complexité. L’enjeu consiste à maintenir un cadre suffisamment structurant, sans freiner les usages.
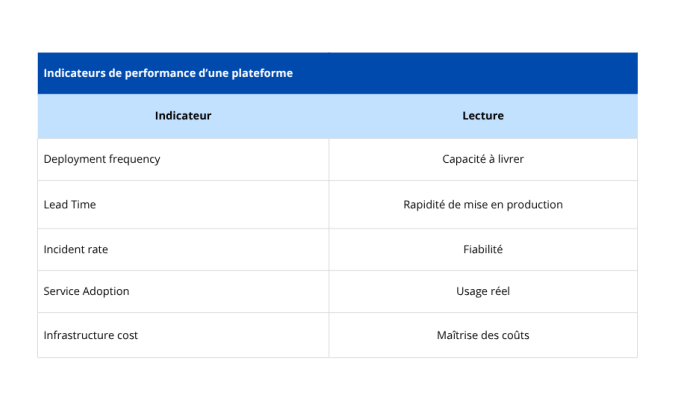
Mesurer le succès post-migration
La performance d’une plateforme ne se limite pas à des critères techniques. Elle se mesure à son impact sur le delivery, les coûts et la fiabilité.
Ces indicateurs permettent d’objectiver les décisions et d’ajuster la trajectoire en fonction des résultats observés.
Faire évoluer la plateforme sans recréer de complexité
Faire évoluer une plateforme implique de conserver un équilibre. Elle doit rester alignée avec les usages, sans multiplier les dépendances ni recréer de dette technique.
Certaines évolutions permettent d’aller dans ce sens. L’architecture micro-frontend, par exemple, facilite l’évolution progressive de certaines briques sans remettre en cause l’ensemble du socle.
Le replatforming n’est alors plus un projet isolé. Il ne s’agit plus seulement de migrer vers un nouvel environnement, mais de poser les bases d’une transformation continue.
Ce cycle — construire, faire évoluer, itérer — structure la manière dont une organisation aborde sa plateforme dans la durée.
Chez Datanumia, cette logique ne s’arrête pas à la migration : la plateforme évolue en fonction des usages, des contraintes techniques et des enjeux métiers.
Le replatforming n’est donc pas une finalité. C’est un point de passage dans une trajectoire plus large, orientée performance, maîtrise des coûts et création de valeur.
Crédits photo : Image de Pixabay - Brian Penny
À découvrir également

Data science au service de l'énergie : comment les algorithmes améliorent la performance énergétique

Platform Engineering : dépasser les limites du DevOps pour construire un socle fiable et flexible
