19 juillet 2021
Les choix qui nous permettent de gérer de manière fiable et efficace les données de 12 millions de compteurs.
L'une des missions de l’équipe Datanumia est de garantir un avenir plus durable pour la planète. Avec 12 millions de consommateurs sur notre plateforme, notre objectif quotidien est de simplifier l'expérience numérique des consommateurs d'énergie. Un des principes qui nous à aider pour cela est l'architecture lambda.
Gérer 12 millions de points de données n'est pas une tâche facile, pour toutes les raisons que vous imaginez : temps de traitement, sécurité, analytique, etc.
De plus, les données énergétiques sont des données sensibles pour les consommateurs. Dès notre premier projet avec EDF, le plus grand distributeur de France, nous avons compris à quel point il était essentiel de disposer d'une plateforme robuste et sécurisée, à laquelle les distributeurs et les consommateurs pouvaient faire confiance.
En tant qu’éditeur de logiciels dans un environnement à fort enjeu, nous avons dû faire des choix technologiques intelligents, compte tenu des changements d'infrastructure en cours dans le secteur de l'énergie. Par exemple, nous savions que les compteurs communicants allaient devenir la norme (60 % de nos points de données proviennent désormais de compteurs communicants). Nous avions donc besoin d'une vitesse de traitement élevée pour de grandes quantités de données.
Ce besoin nous a rapidement orientés vers l'architecture Lambda.
L'idée derrière l'architecture Lambda est d'équilibrer le temps de traitement des données et leur précision en utilisant une combinaison de traitement par lots et de traitement en flux en temps réel.
En d'autres termes, pendant que les données par lots de haute précision sont traitées, les données en flux de moindre précision peuvent être rapidement mises à la disposition de l'utilisateur final. Voici comment cela se passe en pratique pour Datanumia. Un compteur électrique communicant génère un point de données toutes les 5 à 30 minutes. Cela représente plusieurs milliards de points de données par jour pour tous nos clients.
Outre les données des compteurs, nous recevons une variété d'autres points de données de la part des fournisseurs d’énergie, tels que les profils des utilisateurs finaux, les informations sur les contrats, les tarifs, etc.
Les données entrantes sont stockées dans des ensembles de données immuables qui contiennent les données historiques de tous les utilisateurs. Toutes ces données sont traitées dans un lot nocturne afin de calculer la consommation d'énergie, la ventilation de l'utilisation, les comparaisons entre pairs et d'autres informations utiles. Ces informations sont ensuite stockées dans une base de données dédiée. Ce processus se concentre principalement sur la précision en traitant toutes les données.
Cependant, cette approche pose un problème lorsqu'un utilisateur souhaite voir la consommation d'énergie pour la journée en cours : l'utilisateur peut obtenir des informations pas à jour si le lot n'a pas encore été exécuté (bien que nous ayons déjà reçu les relevés de compteur de cet utilisateur).
L'architecture Lambda nous permet de surmonter cette latence.
Lorsque nous recevons des données des fournisseurs d'énergie, nous les envoyons à un autre système qui calcule et stocke exactement les mêmes aperçus que ceux générés par le lot. Les résultats peuvent parfois être moins précis, mais les calculs sont rapides car ils ne sont pas effectués sur toutes les données, mais uniquement sur les dernières données reçues. Par conséquent, lorsque le front-end demande une valeur de consommation d'énergie, un composant intermédiaire est chargé d'exécuter les requêtes sur les différents ensembles de stockage des calculs, de mélanger les résultats et, enfin, de renvoyer les résultats résolus.
Cette architecture nous permet de traiter d'énormes quantités de données et de fournir des informations utiles à la vitesse de l'éclair sans sacrifier trop de précision.
Le schéma ci-dessous résume cette architecture :
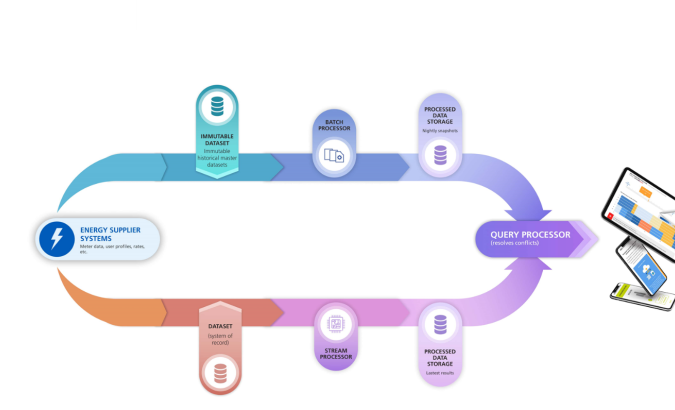
D'un point de vue technique, notre stack est constitué d'un mélange des technologies suivantes : Kafka, Spark, Cassandra et Java classique.
Notre architecture et nos choix d'outils nous donnent l'agilité nécessaire pour :
- Fournir une valeur analytique aux fournisseurs d’énergie
- Evoluer avec le marché au fur et à mesure que les nouvelles technologies, telles que l'IA, sont largement adoptées.
Avec 12 millions de consommateurs sur notre plateforme, Datanumia est le leader de l'engagement client en Europe pour le secteur de l'énergie.
Venez découvrir comment nous aidons les distributeurs d'énergie à mieux engager les clients autour de leur consommation, des appareils connectés, de l'empreinte carbone et de bien d'autres cas d'usage.
Pour plus d'informations ou une démo, n'hésitez pas à nous contacter via le formulaire de contact ou directement via contact@datanumia.com
À découvrir également

Building Automation Systems : tout ce qu’il faut savoir

Data science au service de l'énergie : comment les algorithmes améliorent la performance énergétique
